Watch Video Tutorial: How to configure pagination?
-
Data displayed by websites often span over multiple pages. You can configure WebHarvy to automatically load those pages and extract data.
- 1. Pages with pagination links (next button/link or link to individual pages)
- 2. Pages where pagination links are shown in sets
- 3. Pages with 'Load more content' or 'Display more data' link or button
- 4. Pages where more data is loaded automatically when you scroll down (Infinite Scroll)
- 5. Manually add URLs of next pages
- 6. URL page-number based auto pagination
- 7. Load next page via JavaScript
-
Locate the link within the page, clicking which, the next data page is loaded. Click on the link.
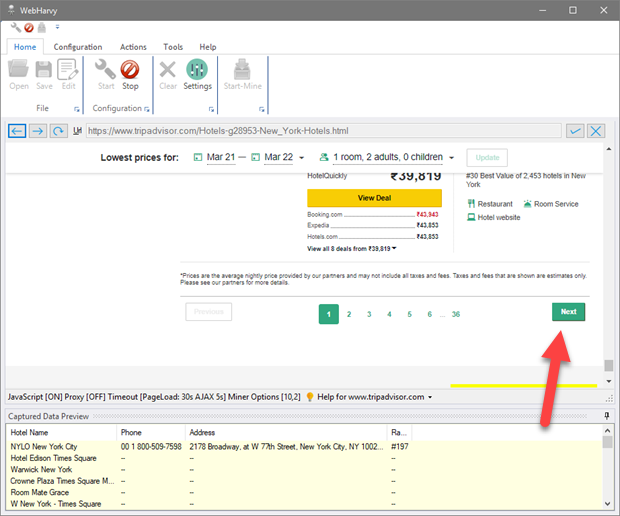
-
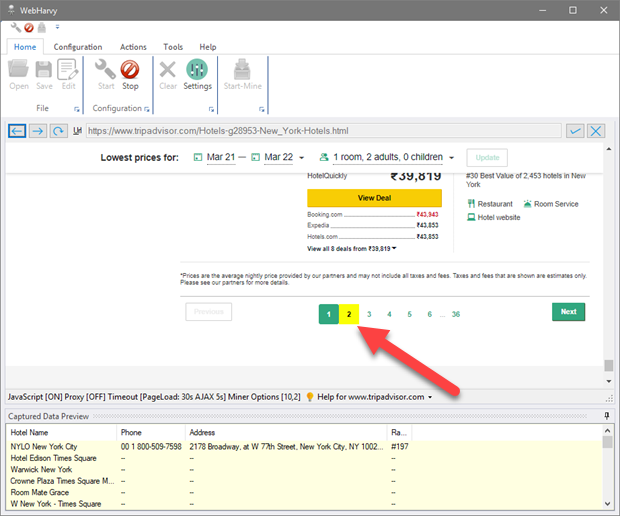
In case there is no 'next page' link, you may also click on the link labeled '2' (link to load the second page) as shown below.
-
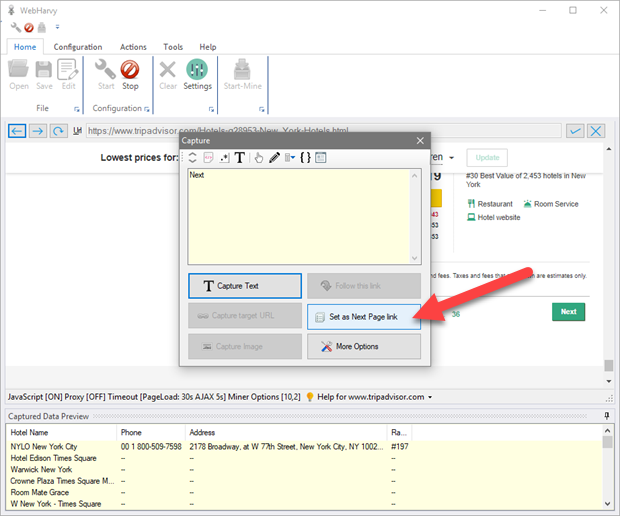
In the resulting Capture window which is displayed, click the 'Set as Next Page link' button.
-
You have now configured WebHarvy to scrape data from multiple pages.

-
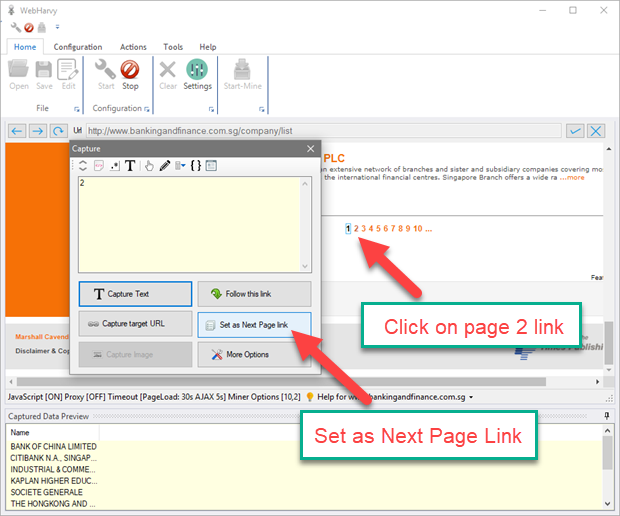
To configure next page link for these type of pages, first click on the direct link to load page number 2 and set it as the next page link.
-
Then, click on the '...' link to load the next set of (10) pages. From 'More Options' select 'Set as 'load next page set' link' option as shown below.
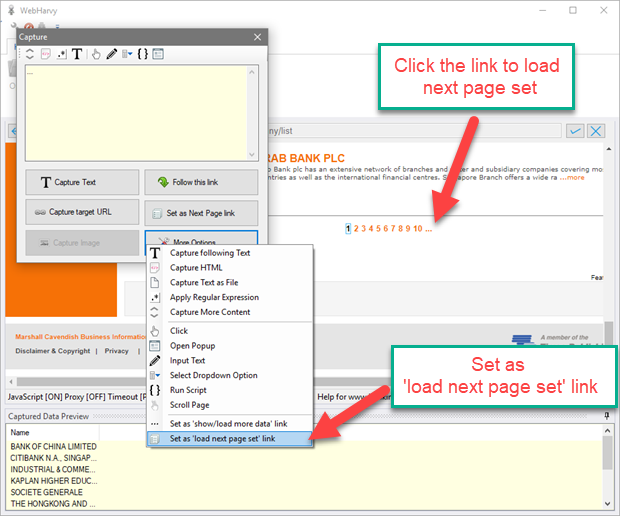
-
During mining WebHarvy will use the page number based next page links to load the first 10 pages and then click the next page set link (...) to load pages 11 to 20.
-
'Load More Content' link or button
In case of websites where more data is loaded when you click on a 'Load more results' (or 'Display more data', 'Show more content') type link or button, WebHarvy can be configured as follows. During configuration, click on the link which loads more data.
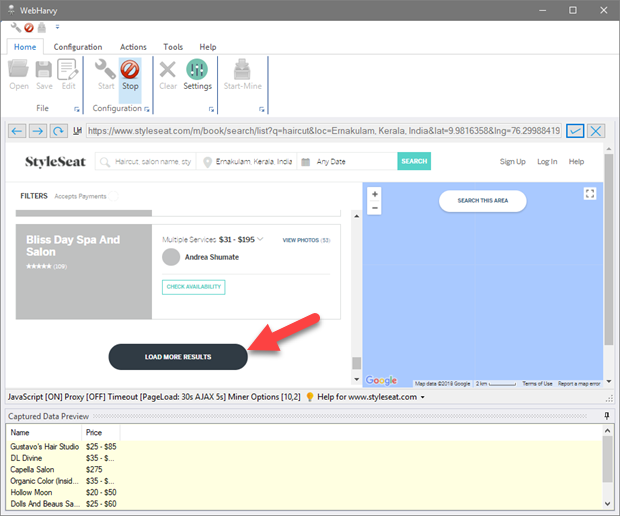
-
In the resulting Capture window displayed, click the 'More Options' button and select 'Set as 'show/load more data' link' option.
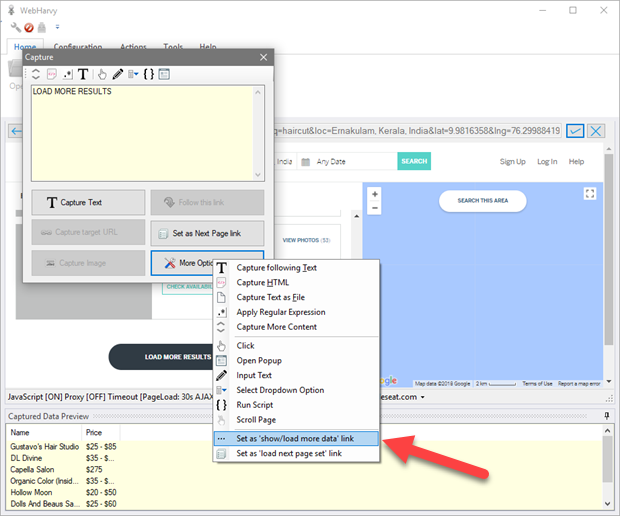
During mining stage you should specify the number of pages to mine since 'Mine all pages' option will be disabled. Increase the 'Script Load Wait Time' value in Miner Settings in case you face any difficulty in getting data from multiple pages by this method. Alternate method of scraping these type of pages
-
Load more data by scrolling down
There are websites which automatically load more data when you scroll down to the end of page. In such cases, during configuration, from the Configuration menu select Scroll to load next page option within Pagination panel.
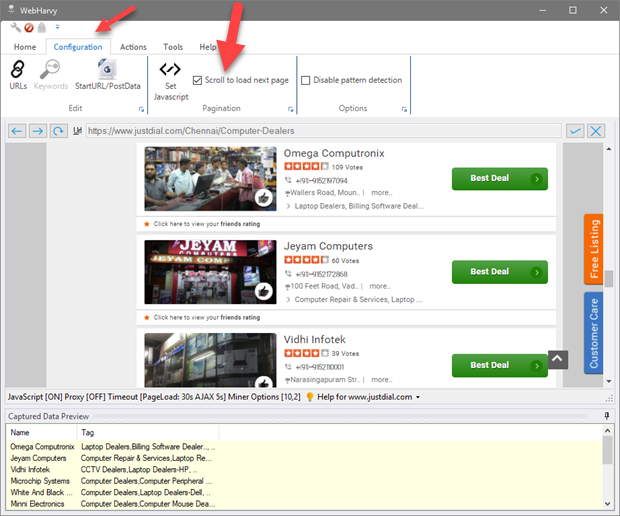
During mining you should specify the number of pages to mine since 'Mine all pages' option will be disabled. Increase the 'Script Load Wait Time' value in Miner Settings in case you face any difficulty in getting data from multiple pages by this method. Alternate method of scraping these type of pages
-
Add additional page URLs manually
During configuration you can click the URLs button within Edit panel of Configuration menu to manually add additional page URLs to the configuration, so that all pages are scraped using the same configuration.
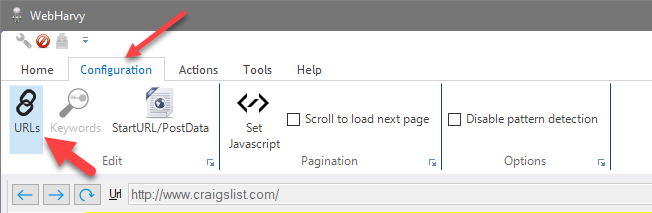
In the resulting window, you may add or delete URLs in the configuration as shown below. All URLs added will be scraped using the same configuration.
You may add absolute as well as relative URLs to the URL list.
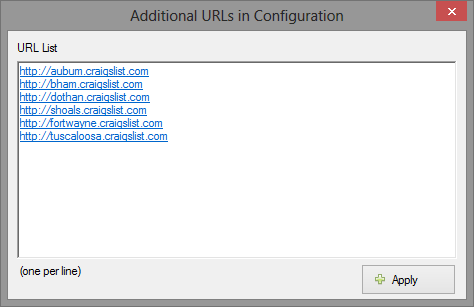
If you have a list of URLs (all belonging to the same domain, which shares the same page layout) you may make use of this feature to scrape all URLs using a single configuration by following the steps given below.
- 1. Open WebHarvy and navigate to the first URL in the list
- 2. Start configuration
- 3. Select required data
- 4. From Configuration menu, click URLs button within Edit panel.
- 5. In the resulting window paste all the remaining URLs in the list and click 'Apply'
- 6. Stop configuration
- 7. Start Mine - all URLs in the list will be scraped using the same configuration
-
URL page-number based auto pagination
If the URLs of next pages can be automatically found by incrementing a page number in the URL string of start page this method can be used. For example, assume the URLs of pages from which you need to scrape data are of the following format.
www.example.com/search/listing?keywords&pageNumber=1
www.example.com/search/listing?keywords&pageNumber=2
www.example.com/search/listing?keywords&pageNumber=3
www.example.com/search/listing?keywords&pageNumber=4
etc..- 1. Open WebHarvy and load www.example.com/search/listing?keywords&pageNumber=1.
- 2. Start configuration
- 3. Select required data from the page, Follow links and select data if required.
- 4. From Configuration menu, click URLs button within Edit panel.
-
5. Paste the following URL and Apply.
www.example.com/search/listing?keywords&pageNumber=%%pagenumber%%
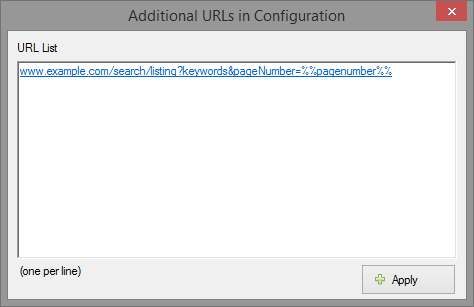
Note that the actual page number is replaced by %%pagenumber%% in the above string.
- 6. Stop configuration
- 7. Start Mine. You should specify the number of pages to mine since 'Mine all pages' option will be disabled. WebHarvy will automatically find and load the next pages and extract data.
-
Load next page via JavaScript
This option allows you to specify a JavaScript code which will be run during mining to load the next page. This can be used when all above methods fail to handle pagination correctly.
The steps to follow are:
1. During configuration, click the Set JavaScript button within Pagination panel of Configuration menu.
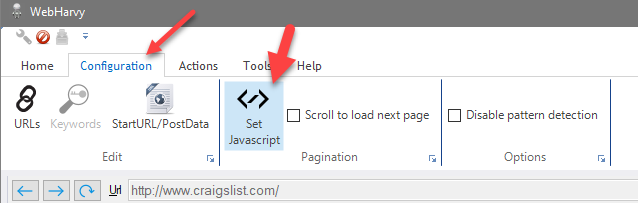
2. In the resulting window, paste the JavaScript code which will load the next page and click OK, as shown below. Select the 'Load Next Page' option if the code loads a new page of data. Select the 'Load More Data' option if the code loads more data in the same page, without loading a new page.

In the above example the code used to load next page is copied below. The code finds the next page button/link and clicks it.
let next=document.getElementsByClassName('next page')[0];next.click();
If the JavaScript code to load next page contains page numbers, then the page numbers should be replaced by %%pagenumber%%. For example, if the code to load page 2 is the following :
javascript:__doPostBack('ctl$gridSearchResults','Page$2')
Then, the code you should use for pagination should be :
javascript:__doPostBack('ctl$gridSearchResults','Page$%%pagenumber%%')
Other than the above there is no need to select next page link during configuration. During mining you will have to provide the number of pages to mine since 'Mine all pages' option will be disabled.
-
When pagination links are not present
While configuring Category Scraping, the first category listings page may sometimes not have pagination links (since there might be only a single page of data). But subsequent categories may have multiple pages of listings.
In such cases, to configure pagination, the following JavaScript code can be used. Assume that the link/button to load next page has the text 'Next'.
next-page=Next
Note that the next link label to be provided is case sensitive. So, you should provide it exactly like how it appears on page.
If the link/button to load second page is labelled 2, then the following code can also be used.
next-page=2
If the next page link/button is labelled '>', then the code to be used is:
next-page = >
In summary, the format of the code to be used is:
next-page = {text label of next page link or button}
Pagination Links
Pagination links with an additional link to load next page set
Some listings show the direct links to load subsequent pages in sets - for example, the following page displays the links to first 10 pages. The '...' link at the end of pagination links should be clicked to load pages 11 to 20.