- 1. Miner Settings
- 2. Browser Settings
- 3. Proxy Settings
- 4. Category / Keyword Settings
- 5. Image Settings
WebHarvy Settings window can be opened from the Home menu by clicking the Settings button.
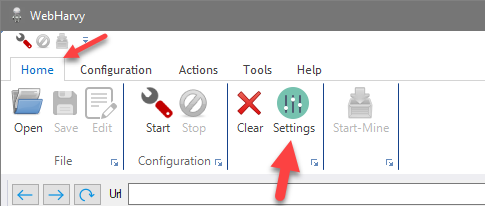
The following tabs are present in the Settings window.
WebHarvy Settings Explained (video)
Miner settings
The Settings window's Miner tab allows you to set the following miner options : Automatic Duplicate Removal, Page Load Timeout, Script Load Wait Time, Automatic Pause Injection, Auto Save Mined Data.
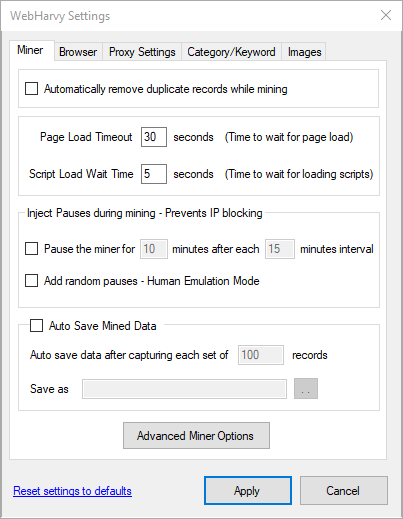
Automatic Duplicate Removal
When this option is enabled, WebHarvy will automatically find and remove duplicate entries while mining data.
Page Load Timeout
The 'Page Load Timeout' value specifies the maximum time up to which WebHarvy should wait for a page to load completely. The default value of this parameter is 30 seconds. This value can made as low as 5 seconds (for high speed connections and fast responding websites) to mine pages faster.
Script Load Wait Time
The 'Script Load Wait Time' value specifies the additional time which WebHarvy miner should wait after the page has been loaded, before parsing data. Default value for this parameter is 5 seconds. Script Load Wait Time value can be increased (as high as 60 seconds or more if required) in case you are facing problems mining data from websites which are slow to respond.
Inject pauses during mining
This options allows you to periodically pause the miner while scraping data. This prevents the miner from making continuous (long time) data requests to the website, thereby minimizing chances of the website blocking your IP. The 'Add random pauses' option adds random wait times after each page load to emulate human behavior.
Auto Save Data
This option helps you prevent data loss. When 'Auto Save Mined Data' option is enabled the miner will automatically save the scraped data to a predefined file on your computer periodically. Periodically saving the data is a good practice and ensures that the data captured over long mining sessions is not lost due to unexpected problems.
Advanced Miner Options
WebHarvy will display the 'Advanced Options' window when you click on the 'Advanced Miner Options' button in Miner settings.
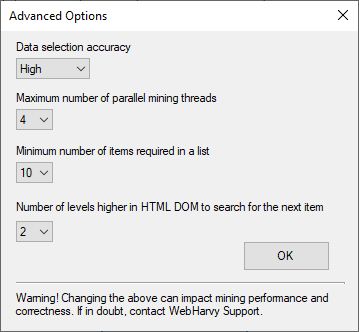
The following settings can be changed from this window.
Data selection accuracy
This setting determines the accuracy with which WebHarvy miner should select data or patterns of data during mining. The default value of this setting is High, and is recommend for most websites. The accuracy value ranges from strict to low. Strict being the highest accuracy, where only exactly similar elements are matched, whereas low will result in lenient rules for matching data.
Note that this setting is available only in WebHarvy versions 6.0 and later.
Maximum number of parallel mining threads
The value of this setting indicates the maximum number of parallel threads used by the miner. When your configuration requires to follow links to scrape data, instead of loading and processing links one after the other, WebHarvy will parallelly load and process links based on this setting. Selecting a higher value for this setting will increase mining speed, but if your system does not have adequate CPU/memory/internet-bandwidth, increasing the number of threads can result in missing data during mining. For computers with more than 4GB of installed memory, the default value of this setting is 4. For computers with less than 4GB RAM, the default value is 1.
Minimum number of items required in a list / Number of levels higher in HTML DOM to search for next item
The default values of these settings are 10 and 2 respectively. These values are tweaked when WebHarvy fails to automatically detect all required items in the starting page of the configuration. See this for example.
Browser settings
Various properties of WebHarvy's internal browser can be changed in the 'Browser' tab of Settings window. These settings apply to both the visual browser, which is used for configuration, and the virtual browser, which is used during mining. For reflecting changes made in the visual configuration browser, application restart is required.
Disable loading images
When 'Disable loading images' option is checked, pages will load faster since image files will not be loaded. This helps to improve mining speed.
Disable element highlighting
During configuration, when the mouse pointer is hovered over elements displayed on page, they are highlighted in yellow. Selecting this option will disable element highlighting during configuration.
Disable opening popups
When WebHarvy's configuration browser encounters a popup/new browser window, it is normally opened in the same browser view itself, since WebHarvy does not support multiple tabs or windows of browser views. Sometimes, this behavior may not be desirable and you might need WebHarvy to ignore the popup window/tab and stay with the parent page. In such circumstances the 'Disable opening popups' option should be selected.
Disable cookies while mining
Enabling 'Disable cookies while mining' option will prevent websites from saving browser cookies locally in your computer. This prevent websites from tracking you and helps avoid IP blocking. For websites which require login to display data, this option should not be enabled.
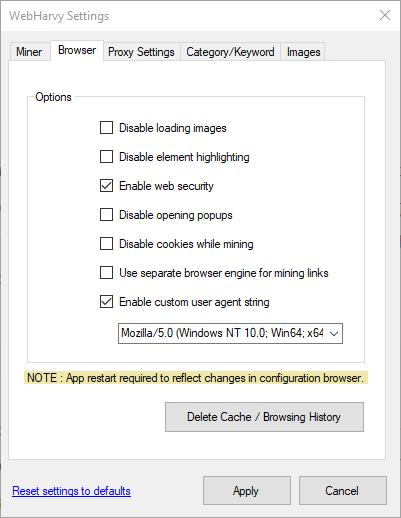
Use separate browser engines for mining links
By default, WebHarvy uses a single browser engine for configuration and mining. When this option is enabled separate engines are used for configuration, for mining listing pages and for mining details pages (by following links from the listing pages). Enabling this option will consume more memory.
Enable custom user agent string
The 'Enable custom user agent string' option allows you to specify a user agent string which WebHarvy configuration and mining browsers will use. This option can be used to make WebHarvy's browser appear like another specific browser (ex: Microsoft Edge, Mozilla Firefox, Google Chrome or Apple Safari) to websites from which you are trying to extract data.
Delete Cache / Browsing history
Clicking the 'Delete Cache / Browsing history' button will delete all browsing history and downloaded items like cookies, cached images / files etc.
Category / Keyword Scraping settings
The 'Category/Keyword' tab in WebHarvy settings window displays the miner settings related with Category/Keyword based scraping.
The Tag with Category/keyword option adds an extra column in the data table while mining configurations which has enabled categories/keywords or has multiple URLs. The additional column will be filled with the category name / keyword or URL related with the captured data. You can also specify the name of this additional column.
When no data is fetched for a category, keyword or URL during mining, enabling the 'Add a blank row with tag when no data is available' option will add a blank row with the corresponding category/keyword/URL filled in the tag column. This helps in identifying the items for which data was not fetched.
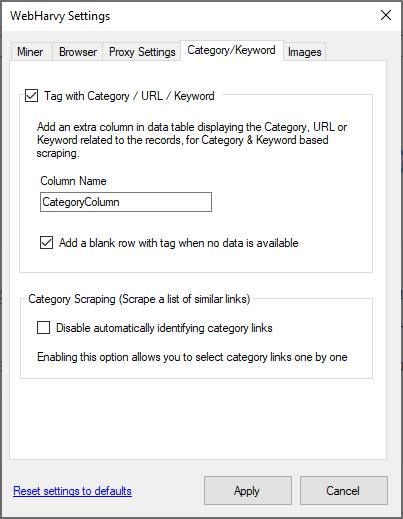
The Disable automatically identifying category links option allows you to select links manually (for Scrape a list of similar links feature), one-by-one (by clicking them one after the other, when you are done selecting links click any empty space to load the first link and start configuration). When this option is enabled, WebHarvy will not try to automatically parse and find the category links.
Image Settings
If your mining configuration includes scraping images, then by default while saving images during mining, WebHarvy gets the image file name from the image URL.
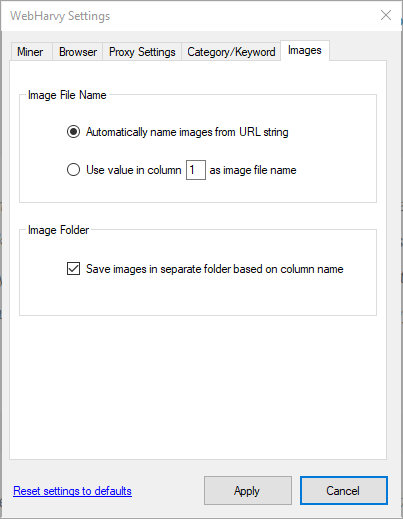
You can also set to save images using a name obtained from another column/cell of the current record. For example, while scraping product details, this allows you save product images with the product name/title as the file name. So if the product title is the second column of data, select the second option in the above window and provide value '2' for the column number.
If the configuration contains multiple image fields, then by default, all images will be downloaded to the same folder which you select during mining. If 'Save images in separate folder' option is selected, then they will be downloaded to separate folders based on their column names.